はじめに
Mac上でオープンソースのペイントソフト「Krita」とStableDiffusionのプラグイン「krita-ai-diffusion」を動かして、ファインチューニングモデルを使った画像生成と、ライブ機能を使った画像生成を行いました。
Kritaの準備
Kritaの準備では、Kritaのダウンロードとインストール、Krita-AI-Diffusionのプラグインの追加を行います。
まずはkritaのページからアプリをダウンロードします。

ダウンロードしたdmgファイルをダブルクリックしKritaをApplicationsにドラッグアンドドロップします。

KritaのプラグインであるKrita-AI-Diffusionを追加します。
以下のページからkrita-AI-Diffusionのプラグインをダウンロードします。

ダウンロードしたプラグインをKritaに追加します。
ツール > スクリプト > Pythonプラグインをファイルからインポートを選択します。

ファイル選択画面が表示されるので先ほどダウンロードした「ai-diffusion.zip」を選択します。
続けてプラグインを有効化するため Krita > Prefarense から設定画面を呼び出します。

PythonプラグインマネージャーからAI Image Diffusionを有効化しKritaを再起動します。

再起動後、新規でドキュメントの作成を行います。画像サイズが大きいと生成に時間がかかるため500x500前後のサイズを指定してください。それ以外の値についてはデフォルト値のままで問題ありません。
初回起動であればウィンドウ内に以下のような「AI-Image-Generation」のパネルが表示されます。

表示されない場合は設定 > ドッキングパネル からAI-Image=Generationにチェックをつけます。

AI-Image-Generationのパネル右上にある歯車マークをクリックして設定を表示します。
設定からAI-Diffusionの環境を構築します。初期設定のままでMacのGPUを使う設定になっているため、特に変更することなく「Install」ボタンをクリックすると構築を開始します。

ファインチューニングモデルの追加
AI-Image-Generationの設定でStyleを開きます。
Model Checkpointのファイルボタンをクリックすることで開くディレクトリに、任意のチェックポイントを追加します。
または、以下のモデルディレクトリを開いて任意のチェックポイントファイルをコピーまたは移動します。
ユーザ/{ユーザ名}/ライブラリ/ApplicationSupport/krita/pykrita/ai_diffusion/.server/ComfyUI/models/checkpoints
Model Checkpointの更新ボタンをクリック後にプルダウンから追加したチェックポイントを選択します。

画像生成の実行
テキストからの画像の生成を実行します。
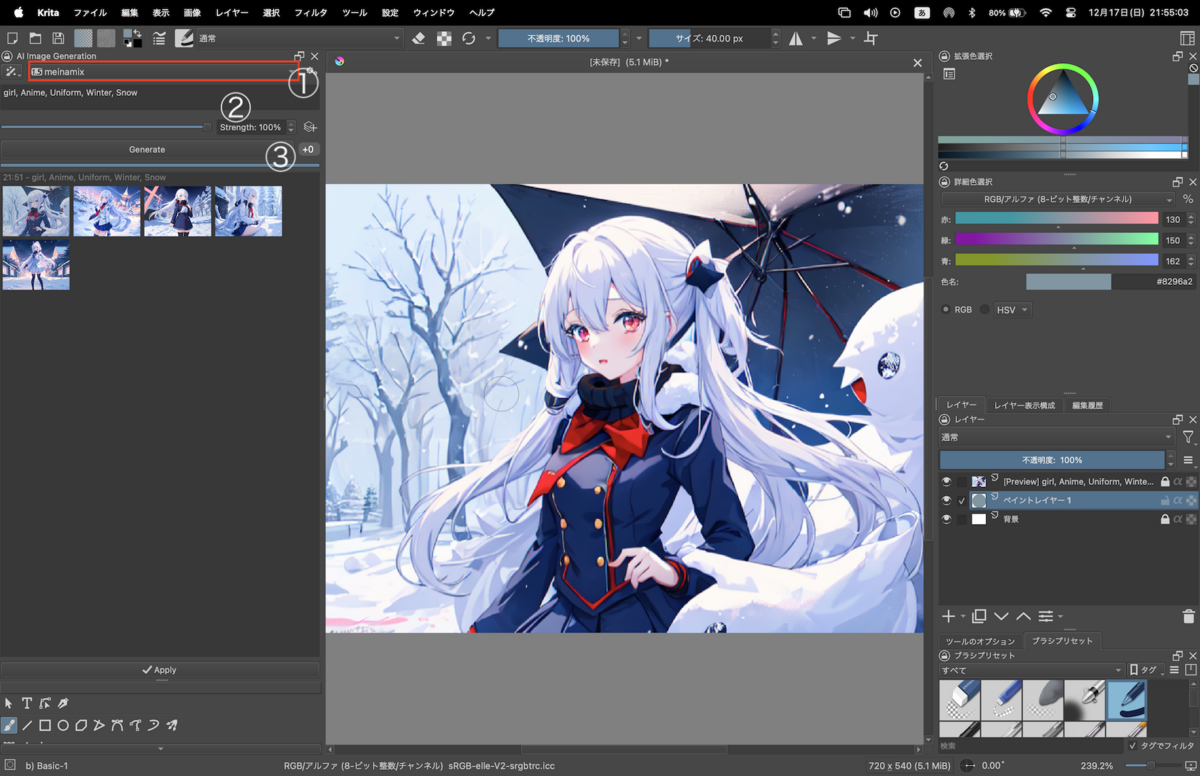
まずは先ほど追加したモデルの選択をします。
続けてプロンプトを入力します。
最後にGenerateボタンをクリックすると画像生成が始まります。
生成が完了するとウィンドウに生成した画像が表示されます。 その中から気に入ったものを選択しApplyをクリックするとキャンバス内に出力されます。
ライブの実行
ライブ機能を使って画像生成を行います。
AI-Image-GenerationからLiveを選択します。

プロンプトの入力とモデルの選択後、再生ボタンを押すとライブ生成が始まります。 キャンバスに書いた絵を元に画像が生成されます。適宜加筆、修正を行いイメージ通りの画像が生成されるように調整してください。また、パネル内の「Strength」はプロンプトをどれだけ反映するかを決める値です。小さい値であれば元の絵の特徴が強く残り、大きい値にすることでプロンプトに合わせた生成が行われるようになります。
ある程度形になったら以下のボタンを押すことで現在の状態がレイヤーとして出力されます。

キャンバスへの加筆修正、レイヤーへの出力を繰り返すことで作りたい画像を生成することができます。
最後にUpScalingを実行して完成になります。

おわりに
Kritaでファインチューニングモデルを使った画像生成と、ライブ機能を使った画像生成を行いました。
ライブ機能を使って画像生成した際は、頭の中で想像した画の輪郭を、AIがどんどんと形にしていく様子に驚きました。また、AIが生成した画の特徴を活かしつつ、自分のイメージに合わせて加筆修正していく作業は、とても楽しかったです。
最後に、アプリおよび関連するリポジトリ等をメンテナンスしている皆様に感謝いたします。